

งาน AI-Powered Automation Summit in Bangkok ประจำปี 2024 ที่ได้จัดโดย UiPath
เมื่อวันที่ 23 เมษายน ณ โรงแรม Siam Kempinski Hotel Bangkok ได้มีการแนะนำเทคโนโลยีใหม่ๆ ของสาย automation ที่น่าสนใจหลายอย่าง
ซึ่งหนึ่งในนั้นคือการพัฒนา large language model ของ UiPath เอง (Specialized LLMs) ขึ้นมาเพื่อนำมาใช้งานกับเครื่องมือ UiPath Document Understanding (DU) ทำให้ประสิทธิ์ภาพการทำงานของ DU เพิ่มขึ้นไปอีกมาก
แต่ก่อนที่จะลงลึกไปที่ Specialized LLMs ที่ว่านี้ ทางออโต้แมทขอเล่าถึงโซลูชั่นการจัดการกับข้อมูลที่ไม่ได้เป็น digital (หมายถึงพวกรูปภาพหรือเอกสารที่ถูกสแกน เป็นต้น) ก่อนว่าเราสามารถนำข้อมูลเกลุ่มนี้เข้ามาใช้งานใน automation process อย่างไร
ในการทำงานกับลูกค้าของเรา เมื่อข้อมูลตั้งต้นที่ต้องนำไปใช้ในขั้นตอนการทำงานต่างๆอยู่ในรูปของเอกสารหรือไฟล์ที่ถูกสแกนมา เช่นการดึงข้อมูล part number จากเอกสาร design specification เพื่อไปจัดทำ BOM ในระบบ ERP หรือการนำรายการยาและอุปกรณ์ทางการแพทย์จากเอกสาร invoice ไปใช้กับกระบวนการเคลมของบริษัทประกัน เป็นต้น ซึ่งเอกสารเหล่านี้ก็มักจะมีลักษณะที่ไม่ตายตัว มีรูปลักษณะที่แตกต่างกันไปแม้เป็นเอกสารชนิดเดียวกัน เราจะนำ UiPath Document Understanding (DU) เข้ามาทำการคัดแยกชนิดเอกสารและดึงข้อมูลที่ต้องใช้ออกจากเอกสารเหล่านี้ ซึ่งผลลัพท์จากการดึงหรืออ่านข้อมูลนี้ก็จะถูกโรบอทในกระบวนการ RPA นำไปทำงานในระบบเคลมหรือระบบ MRP ต่อไป
อย่างไรก็ตาม ถึงแม้ UiPath Document Understanding จะช่วยทำงานดังกล่าวได้เป็นอย่างดีและสามารถก้าวข้ามความท้าทายของการจัดการข้อมูลเอกสารต่างๆเช่น การอ่านภาษาไทย, การอ่าน field พิเศษอย่าง checkbox, การสแกนเอกสารเอียง เป็นต้นได้ก็ตาม เราสังเกตได้ว่าในกรณีที่เอกสารมีความซับซ้อนสูงและมีเอกสารใหม่เข้ามาอยู่เรื่อยๆ การ train AI model ของ UiPath Document Understanding จำเป็นต้องอาศัยข้อมูลเป็นจำนวนมากและใช้เวลาค่อนข้างมากด้วยในการ train ให้ model ดังกล่าวให้เข้าใจเอกสารในระดับที่เกิดความผิดพลาดต่ำ
UiPath เองก็ได้มีการพัฒนาเทคโนโลยีใหม่ๆขึ้นมาเพื่อเพิ่มประสิทธิภาพการทำงานของผลิตภัณฑ์ต่างๆของตนเองรวมทั้ง Document Understanding เพื่อให้ model มีความแม่นยำยิ่งขึ้น โดยเมื่อไม่นานมานี้ UiPath ได้เริ่มรวมเอาความสามารถของ Generative AI หลายอย่างเข้ามาใน Document Understanding เช่นการออก Generative Extractor model เพื่อเพิ่มขีดความสามารถให้ผู้ใช้งานระบุข้อมูลหรือข้อความที่ต้องการดึงจากเอกสารผ่านการทำงานร่วมกับ prompt เช่นการดึงข้อมูล job candidate จากอีเมล เอกสาร resume หรือเอกสารการสมัครงานอื่นๆตามตัวอย่างที่แสดงด้านล่าง

ข้อมูล prompt ดังกล่าวจะถูกส่งไปที่ LLM พร้อมกับข้อมูลของเอกสาร ทำโรบอทสามารถเข้าใจเอกสารได้รวดเร็วกว่าการที่ต้องนำตัวอย่างเอกสารการสมัครงานจำนวนมากเข้ามา train ด้วยตัวผู้ใช้งานเองอย่างเดียว
ทีนี้เรากลับมาที่หัวข้อ Specialized LLMs ที่ได้เกริ่นไว้แล้วข้างบน
การนำความสามารถในการทำงานร่วมกับ GenAI ของ Document Understanding อย่างในกรณีของ Generative Extractor นั้นถือเป็นการทำงานกับ LLM ที่ train เอาไว้แล้วกับชุดข้อมูลที่หลากหลาย (diverse datasets) เพื่อให้สามารถหาคำตอบให้กับผู้ใช้งานที่เป็น generic ซึ่งหมายความว่าพวกเขาอาจถามในเรื่องอะไรก็ได้
กลุ่มของ LLMs ที่เป็น generic หรืออาจเรียกอีกอย่างว่า foundational LLMs เหล่านี้ (GPT-4 คือตัวอย่างหนึ่ง) มีความรอบรู้ในด้านกว้างแต่ก็อาจขาดความรู้ในเชิงลึก เช่นการทำความเข้าใจและดึงข้อมูลที่ถูกต้องออกจากเอกสารที่เราต้องการ พูดอีกอย่างนึงก็คือ ถ้าเราตัดความจำเป็นที่ large language model ต้องเข้าใจในแทบทุกเรื่อง (อย่าง foundational LLMs) เพื่อคลอบคลุมความรู้ที่หลากหลาย และเลือกพัฒนา LLMs ขึ้นมาเพื่อโฟกัสการ train เฉพาะ domain หรือ subject ที่เราสนใจจะใช้งาน เราก็จะได้ model ที่แม่นยำและไม่ต้องใช้เวลา train มากอย่างที่ผ่านมา
ที่คือ Specialized LLMs ที่ UiPath ทำและได้แถลงเปิดตัวเมื่อช่วงปลายไตรมาสที่ 1 ของปีนี้รวมทั้งในงาน AI-Powered Automation Summit ที่กรุงเทพฯ โดย UiPath ได้พัฒนาขึ้นมา 2 model คือ DocPath ซึ่งเป็น LLM ที่พัฒนาขึ้นมาใช้กับ UiPath Document Understanding และ CommPath ซึ่งเป็น LLM ที่พัฒนาขึ้นมาใช้กับ UiPath Communication Mining ซึ่งทั้ง 2 model นี้ถูกสร้างโดยมี core ของฟังชั่นการทำงานเป็น GenAI แต่มีการ train กับเอกสารและ communication messages ที่มีความซับซ้อนเพื่อตอบโจทย์การทำงานที่ต้องอาศัยความรู้ความเข้าใจในเชิงลึก
ฉะนั้น ด้วยการโฟกัสเฉพาะเรื่องที่สนใจแต่สร้าง model ด้วย GenAI ที่มีความสามารถอันมากมาย ผลลัพธ์ซึ่งวัดด้วยความแม่นยำของการทำงานไม่ว่าจะเป็นการคัดแยกชนิดเอกสารหรือการอ่านข้อมูลที่ต้องการจากเอกสารจะสูงกว่า LLMs แบบ generic อื่นๆรวมทั้งตัวของ UiPath Document Understanding เองก่อนหน้าที่จะมี Specialized LLMs อย่างแน่นอน ซึ่ง UiPath ก็ได้เปิดเผยผลการทดสอบภายในที่แสดงให้เห็นว่า UiPath DocPath มีความผิดพลาดโดยเฉลี่ยต่ำกว่า GenAI Model ชั้นนำอยู่ระหว่าง 45% – 76% ด้วยกันเมื่อพิจารณากันเฉพาะความสามารถในการอ่านเอกสารได้อย่างถูกต้อง
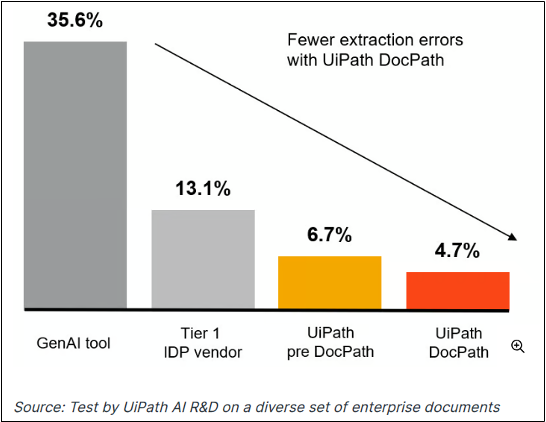
ผลการทดสอบด้านบนแสดงเปอร์เซ็นต์ความผิดพลาดจากการอ่านเอกสาร (Extraction Errors) ของเทคโนโลยีด้านการจัดการเอกสารต่างๆที่นำ AI เข้ามาใช้เพิ่มขีดความสามารถ ซึ่ง UiPath DocPath มีเปอร์เซ็นต์ความผิดพลาดต่ำที่สุดเมื่อเทียบกับกลุ่มเทคโนโลยีที่ยังใช้ Generic LLMs
ฉะนั้นจากความสามารถของเทคโนโลยีการจัดการเอกสารล่าสุด (Intelligent Document Processing) ที่มีการนำ Specialized LLMs เข้ามาร่วมทำงานด้วย ดูเหมือนว่าเราจะก้าวข้ามคำถามที่ว่าจะแยกเอกสารที่ต้องการออกจากเอกสารที่เข้ามาทั้งหมดได้อย่างไรหรือจะอ่านเอกสารที่เป็นแบบ unstructured ได้อย่างไรไปแล้ว แต่เป็นคำถามที่ว่าจะทำอย่างไรให้มี process การทำงานที่ถูกต้องแม่นยำโดยใช้เวลาไม่นานในการ train หรือ retrain AI model ให้สามารถทำงานได้จริง
Credit:







