ถ้าผมถามท่านผู้อ่านบทความที่มีการนำระบบ RPA มาใช้ในองค์กรของท่านแล้วว่า มีใครบ้างที่ไม่เคยคิดถึงหรือไม่ได้นำคุณสมบัติการอ่าน หรือสกัดข้อความจากเอกสารมาเป็นข้อมูลรูปแบบดิจิตอล (Text) ส่วนหนึ่งของโครงการ RPA ผมขอเดาว่าคำตอบคงมีไม่มากนักที่ไม่ได้คิดถึงเลย อันนี้นับรวมทั้งผู้ที่ได้ทำไปแล้วหรือกำลังวางแผนที่จะทำในเฟสถัดไปนะครับ
ที่คิดอย่างนี้ก็เพราะว่าปัญหาอย่างหนึ่งที่แทบทุกธุรกิจต้องประสบก็คือการจัดการกับเอกสาร (paper work) ในแต่ละวัน ข้อมูลปริมาณมหาศาลตั้งแต่งานทรัพยากรบุคคล เอกสารสัญญา ใบสั่งซื้อ ใบแจ้งหนี้ ไหลผ่านทุกองค์กรทั่วโลก ถ้าเราพัฒนาระบบ automation ให้โรบอทเข้ามาทำงานแทนตัวเราได้สารพัดอย่าง ไม่ว่าจะเป็นการนำข้อมูลเข้าออกระบบ ERP การทำรายงาน การรับสส่งอีเมล แต่เรายังต้องมา key ข้อมูลจากกระดาษหรือ scanned document ด้วยมืออยู่ดีก็เป็นเรื่องที่ไม่ค่อยมีประสิทธิภาพเท่าไหร่
ที่ผ่านมาตัวช่วยของเราในเรื่องนี้คือการนำเทคโนโลยี OCR เข้ามาอ่านเอกสารที่สแกนแล้ว แต่ความแม่นยำที่ได้จากการอ่านก็ยังเป็นปัญหาอยู่ดีเมื่อต้องเผชิญกับเอกสารที่
- มีหลายแบบหลายประเภท
- คุณภาพของเอกสารที่สแกนไม่คมขัดนัก มีตำหนิรอยเปื้อน หรือวางเอียงมา
- ต้องมีการอ่านลายมือเขียน
- ต้องมีการอ่านเครื่องหมายถูกผิดจากฟอร์มที่มี checkbox
- เป็นภาษาไทย
- เป็นไฟล์ข้อความหรือรูปภาพสกุลต่างๆเช่น PDF, PNG, GIF, JPEG, TIFF
จากประเด็นปัญหาดังกล่าวทำให้บางครั้งต้องมีการลด scope ของโครงการให้รองรับการอ่านข้อมูลเฉพาะจากเอกสารบางกลุ่มหรือบางลักษณะ เกิดเป็นความท้าทายต่อการประเมินความคุ้มค่าหรือ ROI ของโครงการเนื่องจากเทคโนโลยี OCRเองก็มีค่าใช้จ่ายที่จะคุ้มค่าก็ต่อเมื่อถูกนำมาใช้กับเอกสารปริมาณมาก
นอกจากนี้การพัฒนาโครงการ OCR และ RPA ยังเป็นแบบแยกกันอยู่ กล่าวคือ ระบบ OCR ทำหน้าที่ดึงหรืออ่านข้อมูลตัวอักษรจาก scanned document หรือ image แล้วโรบอทของระบบ RPA เป็นผู้นำข้อมูลที่อ่านได้ไปใช้งานต่อ ทำให้การพัฒนาและการใช้งานไม่เป็นเนื้อเดียวกัน
แต่ถ้าเราสามารถรวบรวมความสามารถด้านการอ่านเอกสารเข้าไปอยู่ในโรบอทเลย ผ่านการเรียนรู้ด้วย Artificial Intelligence (AI) เกิดเป็นซอฟต์แวร์ที่เรียกว่า Intelligent Document Processing (IDP) ซึ่งแก้ปัญหาที่เล่ามาข้างต้นได้ องค์กรย่อมได้รับผลลัพท์ที่ดี (positive impact) จากการที่มี AI เข้ามาช่วยพัฒนาความสามารถของการทำงาน

ทางหน่วยงานของบริษัทวิจัยระดับโลกอย่าง Gartner Financial Practice ได้เคยประเมินไว้ว่า แผนกบัญชีและการเงินขององค์กรสามารถประหยัดชั่วโมงทำงานได้ถึง 25,000 ชั่วโมงจากการลดความผิดพลาดที่เกิดจากพนักงาน (human error) โดยนำเครื่องมือ RPA เข้ามาใช้ในระบบรายงานทางการเงิน ซึ่งตัวเลขของการประหยัดชั่วโมงทำงานนี้ยังสามารถเพิ่มขึ้นได้อีกเนื่องจากในปัจจุบันมีเพียง 1 ใน 3 ของแผนกบัญชีและการเงินในภาพรวมที่ใช้งานระบบ RPA
บทความชุดนี้จะเป็นการให้ข้อมูลแก่ผู้อ่านเกี่ยวกับแง่มุมต่างๆของเทคโนโลยี Intelligent Document Processing และการใช้งานในองค์กร โดยบทความนี้เป็นตอนแรกครับ
Intelligent Document Processing คืออะไร
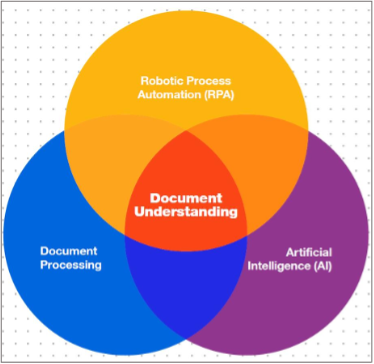
โดยคำอธิบายแล้ว Intelligent Document Processing หมายถึงความสามารถของซอฟท์แวร์โรบอทในการอ่าน การแปลความ และการจัดการกับข้อมูลในเอกสารได้อย่างอัตโนมัติ โดยการนำ machine learning เข้ามาสอนให้โรบอทเรียนรู้และเข้าใจเอกสารที่เราต้องการใช้งาน เราสามารถมอง Intelligent Document Processing เป็นจุดตัดหรือจุดบรรจบกันเทคโนโลยี 3 ส่วนคือ document processing, AI, และ RPA ดังรูปกราฟฟิกด้านล่าง
ในบทความนี้ ผมขอยก Intelligent Document Processing จากค่าย UiPath ที่ชื่อ Document Understanding มาใช้ในการอธิบายประกอบนะครับ
การที่เรานำความสามารถของ document processing และ AI เข้ามารวมกับ RPA ได้หมายถึงเรามีโอกาสที่จะสอนให้โรบอทคิดหรือเข้าใจลักษณะของเอกสารได้เอง แทนที่เราต้องเป็นฝ่ายคิดและสร้าง rule ในการทำงานให้กับโรบอท เพื่อที่โรบอทจะได้ทำงาน step by step ตามคำสั่งเรา
ส่วนวิธีการสอนโรบอทนั้น ขึ้นอยู่กับความซับซ้อนของเอกสารแต่ละประเภทที่ต้องเผชิญ ถ้าเอกสารที่ไม่ซับซ้อนอย่างหนังสือเดินทาง ซึ่งถ้าเราต้องการทราบชื่อหรือสัญชาตของเจ้าของหนังสือเดินทางไม่ว่าเล่มไหน เราหรือโรบอทจะรู้ทันทีว่าต้องดูที่ตำแหน่งไหน แต่ถ้าเป็นเอกสารสัญญา bank statement หรืออีเมลติชมที่ส่งจากลูกค้าของเรา ปัญหาจะเริ่มเกิด เพราะไม่ว่าเราเองหรือโรบอทก็ต้องอ่านเอกสารนั้นทั้งหมดเพื่อจะได้เข้าใจทุกๆส่วนของเอกสาร
Intelligent Document Processing (หรือ Document Understanding ในกรณีของ UiPath) แก้ปัญหานี้โดยการสอนโรบอทให้สามารถแยกแยะประเภทของเอกสาร อ่านข้อมูลได้ถูกตำแหน่ง และนำข้อมูลไปใช้ต่อได้เลยอย่างถูกต้องด้วยความรวดเร็วอย่างที่เราหรือองค์กรของเราต้องการ
เทคนิคและกรรมวิธีในการอ่านข้อมูลจากเอกสาร
โดยทั่วไปเราสามารถจำแนกเอกสารเป็น 3 ประเภท คือ Structured, Semi-structured, และ Unstructured ซึ่งสามารถจัดการได้ด้วยวิธีการอ่านเอกสาร 2 รูปแบบคือแบบ rule-based data extraction (สำหรับเอกสารที่เป็น Structured) และแบบ model-based data extraction (สำหรับ เอกสาร ที่เป็น Semi-structured และ Unstructured)
เทคนิคหรือวิธีการอ่านเอกสารแบบ rule-based หรือบางทีก็เรียก template-based จะเป็นการกำหนด rule แบบตรงไปตรงมา เหมือนการที่เราสร้าง rule ในการบล็อคอีเมลที่เราไม่ต้องการรับหรือการกำหนด key word search สำหรับการค้นหาเฉพาะคำๆนั้นในเอกสาร ถ้าเราต้องการเพิ่มอีเมลที่ต้องการบล็อคหรือ key word search ในการสืบค้น เราต้องเพิ่มชื่ออีเมลหรือ key word เข้าไปเอง
เทคนิคหรือวิธีการอ่านเอกสารแบบ model-based data extraction จะใช้ machine learning (ML) เป็นกลไกในการทำงานด้วยการเรียนรู้จากกลุ่มตัวอย่างจำนวนมาก โดยเราเป็นผู้สอน (train) ให้โรบอทเข้าใจว่าต้องทำอย่างไรในแต่ละสถานการณ์ที่ไม่เหมือนกัน อย่างในตัวอย่างของการบล็อคอีเมลข้างต้น ถ้าเราสามารถสอนให้โรบอทเข้าใจลักษณะของ spam email อันเป็นจุดเริ่มต้นของการที่เราต้องการบล็อคอีเมลไม่ให้เข้ามาได้ คราวนี้ถ้ามีอีเมลจำนวนมากนับร้อยนับพันเข้ามาในองค์กร เราก็ไม่ต้องสร้าง rule หรือกำหนดชื่ออีเมลแต่ละฉบับที่ต้องการบล็อค แต่ให้โรบอทแยกแยะอีเมลที่น่าสงสัยว่าจะเป็น spam email จากการเรียนรู้ของโรบอทเอง
ทั้งสองเทคนิคดังกล่าวหรืออาจรวมอีกหนึ่งเทคนิคคือ hybrid approach ที่เป็นการรวมทั้ง rule-based และ model-based เข้าไว้ด้วยกัน (เช่นกรณีที่บางครั้งการอ่านข้อมูลบางตำแหน่งจากเอกสารประเภท Structured ต้องอาศัย ML model เข้ามาช่วนเพื่อความม่นยำมากขึ้น) สามารถเรียกใช้งานได้จากแพลตฟอร์มของ Document Understanding ที่รวมความสามารถเหล่านี้ไว้ด้วยกัน
การข้ามข้อจำกัดเดิมของการใช้เฉพาะ OCR
คุณสมบัติของ Document Understanding ที่กล่าวมาทำให้เราสามารถก้าวข้ามขีดจำกัดของการใช้เฉพาะโซลูชั่น OCR ร่วมกับ rule-based approach ในการจัดการกับเอกสารที่ไม่ใช่ Structured ซึ่งบางท่านอาจเคยเจอมาบ้างแล้ว ยกตัวอย่างเช่น การจัดการกับกระบวนการใบแจ้งหนี้ (Invoice) ที่ทีม Account Payable (AP) พยายามสร้าง template และใช้ OCR อ่านเอกสารใบแจ้งหนี้ที่สแกนจากกระดาษ จากนั้นก็ส่งต่อให้ RPAนำเข้าระบบเพื่อไปทำการจ่ายหนี้ แต่เนื่องจากฟอร์มใบแจ้งหนี้มีความต่างกันในแต่ละเจ้าหนี้ ทำให้ต้องพัฒนา template จำนวนมากเพื่อให้รองรับความต่างนี้ หรือไม่ก็พยายามทำ template ที่ซับซ้อนให้รองรับฟอร์มใบแจ้งหนี้หลายๆแบบ ซึ่งต้องแลกกับความถูกต้องของการอ่านตัวอักษร ทำให้ผู้ใช้งานมีภาระเพิ่มขึ้นในขั้นตอน validation
แต่พอมาเป็นการใช้งานด้วย Document Understanding ทำให้เรามีทางเลือกเพิ่มขึ้นในการใช้ model-based approach ในการจัดการกับเอกสาร Semi-Structured อย่างใบแจ้งหนี้ โดยอาศัย ML skill model ที่โรบอทได้รับการสอนและเรียนรู้ได้ตลอดเวลาเพื่อเพิ่มความถูกต้องแม่นยำของการอ่านขัอมูล
จากข้อมูลการใช้งานจริงของบริษัทค้าปลีกขนาดใหญ่ของสหรัฐแห่งหนึ่ง ที่ว่าจ้างให้บริษัทที่ปรึกษาด้านระบบอัตโนมัติ ที่ชื่อ Accelirate Inc. พัฒนาระบบ RPA สำหรับกระบวนการใบแจ้งหนี้ (Invoice Processing) พบว่าใบแจ้งหนี้กว่า 93% ของทั้งหมดสามารถจัดการได้โดยไม่ต้องใช้คน (อ่านได้แม่นยำเกินค่าระดับความเชื่อมั่น) ซึ่งบริษัทค้าปลีกนี้มีปริมาณใบแจ้งหนี้โดยเฉลี่ย 200 – 500 ใบต่อวัน หรือกว่า 700 ใบสำหรับวันที่มากที่สุด
ขั้นตอนการทำงานของโรบอทจากเครื่องมือ Document Understanding ที่บริษัทค้าปลีกใช้งานอยู่ มี 6 ขั้นตอนดังต่อไปนี้
- โรบอทอ่านอีเมล คัดแยกอีเมลที่ไม่เกี่ยวกับใบแจ้งหนี้ออกมาแล้วส่งไปให้เจ้าหน้าที่ในทีม AP จัดการแบบ manual ส่วนอีเมลที่เป็นงานใบแจ้งหนี้นั้น โรบอทก็จะบันทึกเอกสารแนบของอีเมลลงบนไฟล์แขร์เพื่อไปเข้าคิวงานของระบบ Document Understanding
- โรบอท digitize ใบแจ้งหนี้ ด้วยเครื่องมือ OCR และหาตำแหน่งบนเอกสารของข้อมูลที่ต้องการอ่าน รวมทั้งแยกชุดเอกสารออกเป็นแต่ละหน้าโดยเรียงลำดับของหน้าอย่างถูกต้อง
- โรบอท extract ข้อมูลที่กำหนดไว้แล้วอย่าง วันที่ใบแจ้งหนี้ หมายเลขใบแจ้งหนี้ จำนวนเงิน วันที่ต้องชำระ เป็นต้น ด้วย machine learning ซึ่งในโซลูชั่นนี้ Accelirate นำ out-of-the-box pre-trained model สำหรับ Invoice ของ UiPathเข้ามาใช้งานร่วมกับการสอนโรบอทให้อ่านข้อมูลได้แม่นยำเพิ่มขึ้นบนแพลทฟอร์ม AI Center ซึ่งเป็นเครื่องมือที่อยู่ในกลุ่มเดียวกันกับ Document Understanding นอกจากใบแจ้งหนี้แล้ว โรบอทยังได้รับการสอนในให้เข้าใจเอกสารและสามารถค้นหาเอกสารแนบอื่นๆอยาง ใบตราขนส่งสินค้า (bill of lading) หรือ BOL ซึ่งเป็นเอกสารที่ต้องใช้ประกอบกระบวนการจ่ายหนี้การค้า ซึ่งโรบอทสามารถตรวจสอบได้ว่าอีเมลที่ส่งเข้ามามี BOL หรือไม่ ถ้าไม่ก็แจ้งทีม AP เพื่อแก้ปัญหาต่อไป
- โรบอทประเมินความถูกต้องของระดับความเชื่อมั่นในการอ่านเอกสาร
- ถ้าโรบอทอ่านข้อมูลจากใบแจ้งหนี้ได้ระดับความเชื่อมั่น 95% ขึ้นไป ข้อมูลจากใบแจ้งหนี้จะถูกส่งต่อแบบอัตโนมัตืไปยังคิวงาน reconcile เพื่อทำจ่ายต่อไป
- ในกรณีที่ระดับความเชื่อมั่นจากการอ่านต่ำกว่า 95% ข้อมูลจากใบแจ้งหนี้จะถูกส่งไปให้เจ้าหน้าที่ทีม AP ทำการ validation เพื่อยืนยันหรือแก้ไขความถูกต้อง
- การทำงานจะย้อนกลับไปที่ขั้นตอนที่ 1 สำหรับการทำงานของใบแจ้งหนี้ลำดับถัดไป จนกระทั่งใบแจ้งหนี้ที่ถูกส่งมาทั้งหมด จะไปอยู่ในคิวงาน reconcile เพื่อเตรียมการอนุมัติจ่าย
- โรบอทจัดทำรายงานสรุปการทำงานของใบแจ้งหนี้ batch นี้ ประกอบไปด้วย จำนวนใบแจ้งหนี้ทั้งหมด จำนวนใบแจ้งหนี้ที่อ่านได้สำเร็จด้วยโรบอทเอง จำนวนใบแจ้งหนี้ที่ต้องส่งให้ทีม AP ทำ validation เวลาที่โรบอททำงานในกระบวนการนี้
จากการประเมินความคุ้มค่าของโครงการ ทีม AP ของบริษัทค้าปลีกแห่งนี้สามารถลดเวลาโดยรวมลงได้ถึง 20% เพื่อที่สมาชิกทีม AP สามารถไปใช้เวลากับเรื่องอื่นที่สำคัญกว่า เนื่องจากเวลาในการจัดการกับใบแจ้งหนี้ลดลงเหลือ 30 วินาทีต่อใบเมื่อเทียบกับ 3-5 นาทีต่อใบก่อนที่จะนำ Document Understanding เข้ามาใช้
ผู้อ่านที่สนใจสามารถติดตามข้อมูลเพิ่มเติมจากบทสัมภาษณ์ของผู้รับผิดชอบโครงการจาก Accelirate Inc. ซึ่งเป็นบริษัทที่ปรึกษาที่พัฒนาโครงการดังกล่าวได้ตามลิงค์วิดิโอด้านล่าง
ในบทความตอนต่อไปของชุด สอนโรบอทให้เข้าใจเอกสาร จะให้ข้อมูลเชิงลึกที่มากขึ้นของ Document Understanding ขอให้รอติดตามทาง blog ของบ.ออโต้แมทนะครับ
แล้วพบกันใหม่ สวัสดีครับ