

บทความนี้สรุปจาก Webinar UiPath Thailand ในหัวข้อ “ทำไม OCR / ทำเองด้วย LLM ยังไม่พอ และ UiPath IXP ช่วยให้องค์กรอ่าน-ดึงข้อมูล-ควบคุมคุณภาพเอกสารได้แบบใช้งานจริง” เขียนเพื่อให้อ่านเข้าใจง่าย ได้สาระ และนำไปต่อยอดได้จริงโดยไม่เน้นเทคนิคเชิงลึก
ทำไม automation ถึงยัง "ไปไม่สุด" ทั้งที่มี RPA แล้ว?
ในช่วง 5-7 ปีที่ผ่านมา องค์กรจำนวนมากทั่วโลกและในประเทศไทยได้นำ RPA (Robotic Process Automation) มาใช้งานอย่างแพร่หลาย ตั้งแต่งานป้อนข้อมูล การกรอกฟอร์ม การดึงข้อมูลจากระบบหนึ่งไปอีกระบบ ไปจนถึงการส่งอีเมลแจ้งเตือนอัตโนมัติ บอตเหล่านี้ทำงานได้ดีในสภาพแวดล้อมที่ “เป็นขั้นตอน” ชัดเจน มีหน้าจอเดิม ฟิลด์เดิม และกระบวนการที่ไม่ค่อยเปลี่ยน เพื่อตอบโจทย์งานด้าน automation พื้นฐาน
แต่เมื่อถามถึง End-to-End Automation คือการทำให้กระบวนการทางธุรกิจทั้งสายวิ่งได้โดยอัตโนมัติตั้งแต่ต้นจนจบ ปัญหาที่ทุกองค์กรเจอเหมือนกันคือ มักมีคอขวดบางจุดที่บอตยังข้ามไม่ได้ และคอขวดนั้นแทบทุกครั้งคือ เอกสาร
เอกสารในที่นี้ไม่ได้หมายถึงแค่ไฟล์ PDF หรือรูปถ่าย แต่รวมถึง Email พร้อม attachment ทุกรูปแบบ ทั้งใบแจ้งหนี้ (Invoice) ที่มาจากคู่ค้าหลายสิบเจ้าและมีรูปแบบต่างกันไปทุกเจ้า เอกสารสแกนที่บางทีเอียงหรืออ่านยาก ตารางที่ซับซ้อนและมีการผสมข้อมูลหลายชนิด หรือแม้แต่ไฟล์เดียวที่บรรจุเอกสารหลายชนิดรวมกัน (Packet Documents) เช่น ใบคำร้อง ใบเสร็จ และสำเนาบัตรประชาชน มาในไฟล์เดียว
สรุปคือ RPA เก่งมากในเรื่อง “กระบวนการที่มีโครงสร้าง” แต่ “เอกสารและการสื่อสาร” คือโลกที่ไม่มีโครงสร้างตายตัว และนั่นคือจุดที่ RPA อย่างเดียวทำได้ไม่ครบ
ใบ Invoice จากคู่ค้าหลายเจ้า แต่ละเจ้ามีเทมเพลตของตัวเอง บางเจ้าส่งเป็น PDF บางเจ้าส่งเป็นภาพถ่าย บางเจ้ามีตารางซับซ้อน ระบบที่ไม่ยืดหยุ่นพอจะสะดุดทันที
Packet Document หรือไฟล์รวมหลายเอกสาร เช่น ส่งเอกสารเคลมประกันมาไฟล์เดียว แต่ข้างในมีทั้งใบคำร้อง ใบรับรองแพทย์ ใบเสร็จค่ารักษา ระบบต้องแยกก่อน ถึงจะดึงข้อมูลได้ถูกต้อง
แม้จะอ่านออกด้วย OCR หรือดึงข้อมูลได้ แต่ถ้าไม่มีระบบตรวจสอบว่า accuracy ระดับไหน จุดไหนที่ผิดพลาดบ่อย หรือ compliance ตามหลักธรรมาภิบาลหรือเปล่า ก็ใช้งานจริงในระดับองค์กรไม่ได้
OCR อย่างเดียวไม่พอ และ "ทำเองด้วย LLM" ก็มีต้นทุนแฝง
เมื่อเจอปัญหาเรื่องเอกสาร หลายทีมมักคิดถึงสองทางแก้ไขทันที คือใช้ OCR หรือสร้างโซลูชันเองด้วย LLM (Large Language Model) ซึ่งทั้งสองแนวทางนี้มีเหตุผลดีที่จะลอง แต่ก็มีข้อจำกัดที่สำคัญและมักถูกมองข้ามในช่วงเดโม
OCR: เริ่มต้นดี แต่ยังไม่ครบ
OCR (Optical Character Recognition) คือเทคโนโลยีที่แปลงภาพหรือเอกสารสแกนให้เป็นข้อความที่เครื่องอ่านได้ ในช่วงทศวรรษที่ผ่านมา OCR พัฒนาขึ้นมากจนอ่านตัวอักษรได้แม่นยำกว่าเดิมมาก แต่ OCR ทำได้แค่ “อ่านออก” เท่านั้น
งานจริงที่ต้องทำต่อหลังจาก OCR ยังมีอีกมาก ไม่ว่าจะเป็นการแยกว่าข้อความไหนคือ “ชื่อ” ข้อความไหนคือ “มูลค่า” ข้อความไหนคือ “วันที่” การจัดกลุ่มข้อมูลตามโครงสร้างของเอกสารแต่ละประเภท การเชื่อมต่อกับ workflow downstream เช่น ป้อนข้อมูลเข้าระบบ ERP หรือ CRM และการตรวจสอบว่าข้อมูลที่ดึงมาถูกต้องหรือไม่ก่อนนำไปใช้งาน OCR จึงเป็นแค่จุดเริ่มต้น ไม่ใช่จุดสิ้นสุด ของระบบ automation ที่สมบูรณ์
OCR vs IDP ต่างกันอย่างไร? เปรียบเทียบเทคโนโลยีจัดการเอกสารอัจฉริยะในยุค Automation
เจาะลึกความแตกต่างระหว่างการใช้เทคโนโลยี OCR แบบดั้งเดิม กับ IDP เทคโนโลยีไหนตอบโจทย์และคุ้มค่าสำหรับธุรกิจคุณมากกว่ากัน?
อ่านบทความนี้ คลิกเลย!DIY LLM: ยืดหยุ่นในเดโม แต่เป็นหนี้เทคนิคในโปรดักชัน
แนวทางที่สองที่ได้รับความนิยมในช่วงปีที่ผ่านมาคือ การสร้างโซลูชันเองโดยใช้ LLM เช่น GPT, Claude, หรือโมเดลอื่น ๆ มาช่วยอ่านและดึงข้อมูลจากเอกสาร ในช่วงทดสอบหรือ Proof of Concept (PoC) แนวทางนี้มักให้ผลดูดีมาก เพราะ LLM มีความยืดหยุ่นสูง สามารถ prompt ให้ทำงานกับเอกสารหลากรูปแบบได้
แต่ความท้าทายที่ทีม IT และ Automation ต้องเผชิญเมื่อนำไปใช้งานจริงในระดับ Production มีหลายประการที่หนักมาก
Scope ยากและมักบาน: การกำหนดว่าระบบควรรองรับเอกสารประเภทไหน ฟิลด์อะไรบ้าง และ edge case แบบไหนนั้นยากกว่าที่คิดมาก และมักมีการขยายขอบเขตออกไปเรื่อย ๆ
ต้องทดลองหลายโมเดลหลาย Use Case: แต่ละประเภทเอกสารอาจต้องการโมเดลหรือ prompt strategy ที่ต่างกัน การบำรุงรักษาหลายโมเดลพร้อมกันต้องใช้ทรัพยากรมาก
เปลี่ยน Prompt หรือ Schema แล้วผลกระทบตามไม่ทัน: เมื่อมีการแก้ไข prompt ผลลัพธ์อาจเปลี่ยนไปอย่างไม่คาดคิดในเอกสารประเภทอื่น และการ test ให้ครบทุก case ใช้เวลามาก
Governance/Validation/Measurement ทำยาก: การสร้างระบบตรวจสอบ audit trail และวัดผลความแม่นยำในระดับ enterprise ต้องพัฒนาเองทั้งหมด
Technical Debt สูง ดูแลระยะยาวลำบาก: โซลูชันที่สร้างเองมักขึ้นอยู่กับผู้พัฒนาเพียงไม่กี่คน และยากต่อการส่งต่อหรือ scale
Webinar สรุปประเด็นนี้ไว้ได้ชัดมากว่า “เดโมอาจไว แต่การทำให้เสถียรและตรวจสอบได้คือของจริงที่องค์กรต้องการ” ประโยคนี้ตรงใจมาก เพราะในโลกจริงองค์กรต้องการความน่าเชื่อถือ ไม่ใช่แค่ความฉลาด
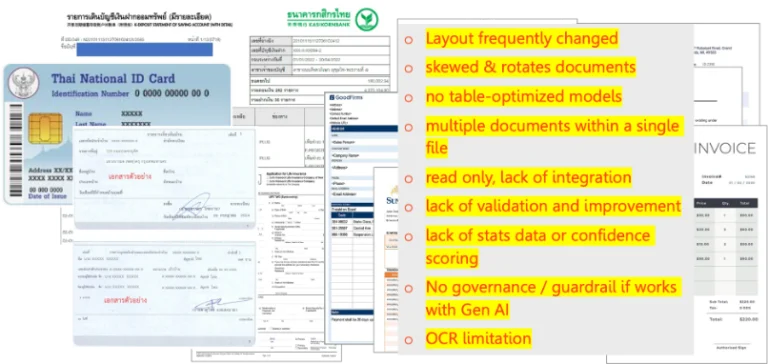
UiPath IXP คืออะไร แบบที่เข้าใจง่ายและนำไปใช้ได้จริง
UiPath IXP หรือ Intelligent Xtraction & Processing คือแนวทาง Intelligent Document Processing (IDP) ของ UiPath ที่ถูกออกแบบมาตอบโจทย์ “ระดับองค์กร” โดยเฉพาะ ไม่ใช่แค่เครื่องมืออ่านเอกสาร แต่เป็นแพลตฟอร์มที่รวมความสามารถหลายด้านเข้าด้วยกัน ซึ่งก้าวข้ามขีดจำกัดของ OCR ทั่วไป
หัวใจของ UiPath IXP คือแนวคิด Multi-Modal Processing ซึ่งหมายความว่าระบบไม่ได้ถูกออกแบบให้ทำงานได้กับเอกสารประเภทเดียว แต่รองรับทุกประเภทที่องค์กรต้องเผชิญ
สิ่งที่ UiPath IXP ทำได้ครอบคลุม 3 มิติหลัก
Document Understanding: รองรับทั้ง Structured Document เช่น ฟอร์มมาตรฐานที่มีกล่องกรอกข้อมูล และ Semi-Structured Document เช่น Invoice, Receipt, Purchase Order ที่รูปแบบอาจต่างกันแต่ข้อมูลหลักเหมือนกัน
Communications Mining: เข้าใจ Email และข้อความสื่อสารรูปแบบอื่น ๆ ที่ไม่ใช่เอกสารทั่วไป โดยสามารถดึง Intent ของผู้ส่ง ดึงข้อมูลสำคัญ และ route งานให้อัตโนมัติ
Generative Extraction: สำหรับเอกสารที่ Unstructured มาก เช่น สัญญา หนังสือราชการ หรือเอกสารที่มีเนื้อหาหลากหลาย UiPath IXP สามารถใช้ Generative AI ช่วยดึงข้อมูลในบริบทที่ซับซ้อน
จุดเด่นของ UiPath IXP ที่สำคัญสำหรับองค์กร
Webinar เน้นย้ำว่า UiPath IXP ถูกออกแบบมาให้ “พร้อมใช้งานจริง” ซึ่งต่างจากการสร้างเองตรงที่
เริ่มได้เร็ว (Inference-First / Out-of-the-Box): มี Pre-built Model สำหรับเอกสารทั่วไปหลายประเภท ไม่ต้องเริ่มจากศูนย์
ปรับแต่งได้แบบ Configurable / No-Code: สามารถเพิ่ม field ใหม่ ปรับ model หรือเพิ่ม validation rule ได้โดยไม่ต้องเขียนโค้ดทั้งหมดใหม่
มี Guardrails ด้าน Data Protection และ Compliance: เหมาะกับองค์กรที่อยู่ในอุตสาหกรรมที่มีกฎระเบียบเข้มงวด เช่น การเงิน ประกัน หรือสาธารณสุข
มี Model Evaluation และสถิติระดับ Field: สามารถวัดได้ว่า field ไหนระบบอ่านได้แม่นแค่ไหน จุดไหนที่ต้องการการปรับปรุง
รองรับ Human-in-the-Loop: ระบบสามารถ flag เฉพาะเอกสารหรือ field ที่ confidence ต่ำให้คนตรวจ ทำให้ไม่ต้องตรวจทุกชิ้น แต่ก็ไม่พลาดงานสำคัญ
Framework สำหรับเริ่มต้น: แบ่งเอกสาร 3 ประเภท
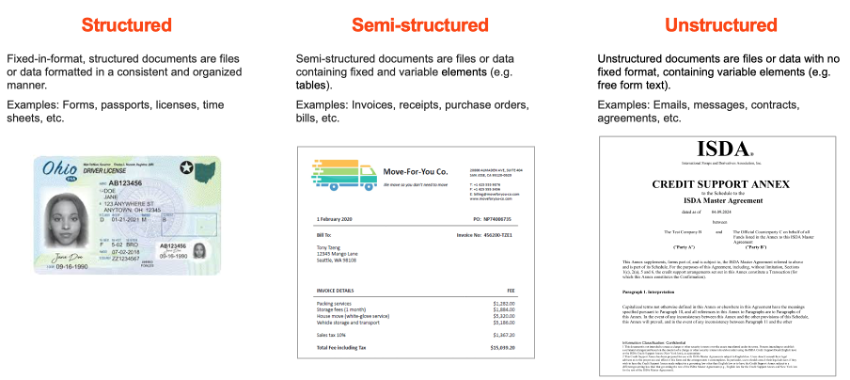
หนึ่งในคำแนะนำที่ Webinar ให้ไว้และมีคุณค่ามากสำหรับทีมที่จะเริ่มต้นใช้งาน IDP คือการเริ่มจากการ “จำแนกประเภทเอกสาร” ก่อน เพราะโจทย์และวิธีการจัดการจะต่างกันโดยสิ้นเชิง
ประเภทที่ 1: Structured Document
เอกสารประเภทนี้มีโครงสร้างตายตัว ชัดเจน เช่น ฟอร์มที่มีกล่องกรอกข้อมูล แบบฟอร์มมาตรฐานของภาครัฐ หรือเอกสารที่ถูกพิมพ์ออกมาจากระบบที่กำหนดรูปแบบไว้แล้ว เอกสารประเภทนี้ดึงข้อมูลได้ง่ายที่สุด เพราะระบบรู้ว่าข้อมูลแต่ละชนิดอยู่ตรงไหนของหน้ากระดาษ
ประเภทที่ 2: Semi-Structured Document
เป็นประเภทที่พบมากที่สุดในงานธุรกิจ เช่น Invoice, Receipt, Purchase Order, Statement of Account ลักษณะคือมีข้อมูลประเภทเดียวกัน (เช่น เลขที่เอกสาร วันที่ มูลค่า ชื่อผู้ส่ง) แต่ layout และรูปแบบต่างกันไปตามผู้ออกเอกสาร IDP ที่ดีต้องสามารถเรียนรู้และปรับตัวกับความหลากหลายนี้ได้
ประเภทที่ 3: Unstructured Document
คือเอกสารที่ข้อมูลอยู่ในรูปแบบข้อความอิสระ เช่น สัญญา จดหมายทางธุรกิจ Email รายงาน หรือบันทึกการประชุม การดึงข้อมูลจากเอกสารประเภทนี้ต้องการ AI ที่ “เข้าใจบริบท” ไม่ใช่แค่จำตำแหน่ง นี่คือจุดที่ Generative AI เข้ามามีบทบาท
ทำไมการจำแนกประเภทก่อนจึงสำคัญ? เพราะเมื่อรู้ประเภท การออกแบบ Extraction Logic, Validation Rules และ Downstream Workflow จะทำได้คมกว่า และวัดผลได้ชัดกว่า แทนที่จะสร้างระบบขนาดใหญ่ที่พยายามทำทุกอย่างพร้อมกันและทำได้ไม่ดีอะไรเลย
เอกสาร 3 โจทย์ที่ต้องตอบพร้อมกัน
Webinar ยังได้ย้ำสิ่งที่หลายองค์กรมักมองข้าม นั่นคือการจัดการเอกสารระดับองค์กรต้องตอบโจทย์สามข้อพร้อมกัน ไม่ใช่ข้อใดข้อหนึ่ง
อ่านและดึงข้อมูลได้แม่น หมายความว่าระบบต้องไม่แค่ “เห็น” ข้อความ แต่ต้องดึงข้อมูลที่ถูกต้อง ครบถ้วน และจัดหมวดหมู่ได้ถูกต้องว่าข้อมูลไหนคืออะไร การใช้เทคโนโลยี OCR ขั้นสูงช่วยตอบโจทย์ส่วนนี้
ตัดสินใจและ Route งานได้ถูกต้อง เมื่อดึงข้อมูลออกมาแล้ว ระบบต้องเข้าใจว่าเอกสารนี้ควรไปไหน ต้องทำอะไรต่อ หรือต้องส่งให้ใคร เช่น Invoice ที่เกินวงเงินอนุมัติต้องส่งให้ผู้บริหารตรวจ ในขณะที่ Invoice ปกติเข้ากระบวนการอัตโนมัติได้เลย
มีระบบควบคุมคุณภาพ วัดผล และ Governance องค์กรต้องตอบได้ว่า ระบบมี accuracy เท่าไหร่ มี audit trail ไหม ใครเข้าถึงข้อมูลได้บ้าง และ compliance ตามข้อกำหนดของอุตสาหกรรมหรือเปล่า
โซลูชันที่ตอบได้แค่ข้อแรกหรือสองข้อ ในระยะยาวจะกลายเป็นภาระมากกว่าประโยชน์ เพราะองค์กรต้องสร้างชั้นการจัดการเพิ่มเติมเองทั้งหมด
บทสรุป: ถ้าจะ Scale automation ต้องปลดล็อก Unstructured Data
ภาพที่ได้จาก Webinar ตอนแรกนี้คือแผนที่ที่ชัดเจนว่า ทำไมองค์กรที่มี RPA อยู่แล้วยังต้อง “เพิ่มชั้น” ของ Intelligence เข้ามา
เมื่อบอตทำงานได้ดีในงาน Structured Process แต่เอกสารและการสื่อสารยังเป็น Unstructured Data ที่คนต้องมานั่งอ่านและป้อนข้อมูลเอง ก็แปลว่ายังมีคอขวดที่ยังไม่ได้แก้ และนั่นคือจุดที่ Intelligent Document Processing เข้ามาเติมเต็ม
UiPath IXP ไม่ได้เป็นแค่ “เครื่องอ่านเอกสารที่ฉลาดขึ้น” แต่คือแพลตฟอร์มที่ออกแบบมาให้รองรับความซับซ้อนของงานเอกสารระดับองค์กร ทั้งในแง่ความหลากหลายของเอกสาร ความต้องการด้าน governance และการวัดผลทางธุรกิจ ขับเคลื่อนกระบวนการ automation ไปอีกระดับ
สิ่งที่ Webinar เน้นและเป็นจุดสำคัญสำหรับทีมที่กำลังพิจารณาลงทุนกับ IDP คือ เริ่มจากการจำแนกเอกสารที่มีให้ชัด เข้าใจโจทย์ทั้ง 3 ข้อ แล้วเลือกโซลูชันที่ตอบโจทย์ระยะยาวได้จริง ไม่ใช่แค่ดูดีในเดโม
ใน Episode II เราจะเจาะลึกต่อว่า UiPath IXP ทำงานกับ Use Case จริงได้อย่างไร วัด ROI แบบไหน และมีแนวทาง Playbook ของ Automat Consulting ที่ช่วยให้ UiPath IXP ขึ้นโปรดักชันได้จริงโดยไม่หลุดกรอบ
พร้อมยกระดับองค์กรของคุณแล้วหรือยัง?
สำหรับองค์กรใดที่กำลังมองหาโซลูชัน Automation หรือต้องการคำปรึกษาด้านเทคนิคเชิงลึกเพื่อเริ่มทรานส์ฟอร์มธุรกิจ ทีมงาน Automat Consulting พร้อมเป็นผู้ช่วยขับเคลื่อนความสำเร็จของคุณด้วยเทคโนโลยีที่ดีที่สุดครับ
ติดต่อรับคำปรึกษาจากเรา





