สวัสดีทุกท่านอีกครั้งครับ
เรายังอยู่ในซีรี่การสอนโรบอทให้เข้าใจเอกสารซึ่งในตอนที่แล้ว เราได้พูดถึงเทคโนโลยี Intelligent Document Processing (IDP) ที่มีการนำ AI เข้ามาเสริมการใช้งานของฟังชั่น OCR และทำให้โรบอทสามารถอ่านข้อมูลจากเอกสารได้หลากหลายชนิดมากขึ้นทั้งเอกสารที่เป็นแบบ semi-structured และแบบ unstructured ผ่านการนำ machine learning models เข้ามาวิเคราะห์รูปแบบของเอกสาร นอกเหนือไปจากการอ่านข้อมูลของเอกสารแบบ structured ที่ OCR ทำได้อยู่แล้ว
ในตอนที่ 2 นี้ เราจะมาลงในรายละเอียดเพิ่มเติมสำหรับบางขั้นตอนที่สำคัญของงาน IDP อย่าง
- การ classify ชนิดของเอกสาร
- การ extract ข้อมูลจากตัวของเอกสาร
- และการทำ validation ข้อมูลที่อ่านออกมาโดยผู้ใช้งาน เพื่อแก้ข้อมูลที่อ่านผิดและช่วยเหลือโรบอทให้พัฒนาการอ่านให้แม่นยำขึ้น
ส่วนขั้นตอนทั้งหมดของงาน IDP ผมได้อธิบายไว้ในตัวอย่างการอ่านข้อมูลจากใบแจ้งหนี้ของบทความที่แล้ว ท่านที่สนใจสามารถย้อนกลับไปอ่านในบทความตอนที่ 1 ได้ครับ
การ classify ชนิดของเอกสาร
เพื่อให้การนำ IDP มาใช้กับระบบอัตโนมัติที่เกี่ยวข้องกับเอกสารในองค์กร้เกิดความคุ้มค่า ระบบ IDP ควรจะต้องถูกใช้กับเอกสารหลายชนิดเพื่อลดงาน manual ในการ key ข้อมูลจากเอกสารเข้าระบบให้มากที่สุด การ classify ชนิดของเอกสารจะเกิดขึ้นเมื่อเรามีเอกสารที่ต้องการอ่านมากกว่า 1 ชนิด เช่นในกระบวนการสรุปยอดค่าใช้จ่ายที่ต้องรวบรวมทั้ง ใบเสร็จ ใบกำกับภาษี ใบรับรองแพทย์ บิลน้ำมัน ฯลฯ ซึ่งโรบอทต้องเข้าใจว่าเอกสารที่ตัวเองกำลังอ่านอยู่นั้น เป็นเอกสารชนิดใด
หรือในกรณีที่เราต้องการอ่านข้อมูลจากเอกสารเพียงบางหน้าเท่านั้นจากชุดเอกสารหลายหน้าที่ถูกส่งเข้ามา ซึ่งในกรณีนี้ เอกสารทั้งชุดต้องถูก classify เพื่อแยกเฉพาะหน้าที่โรบอทต้องอ่านข้อมูลออกจากหน้าอื่นในชุดเอกสารที่เหลือ
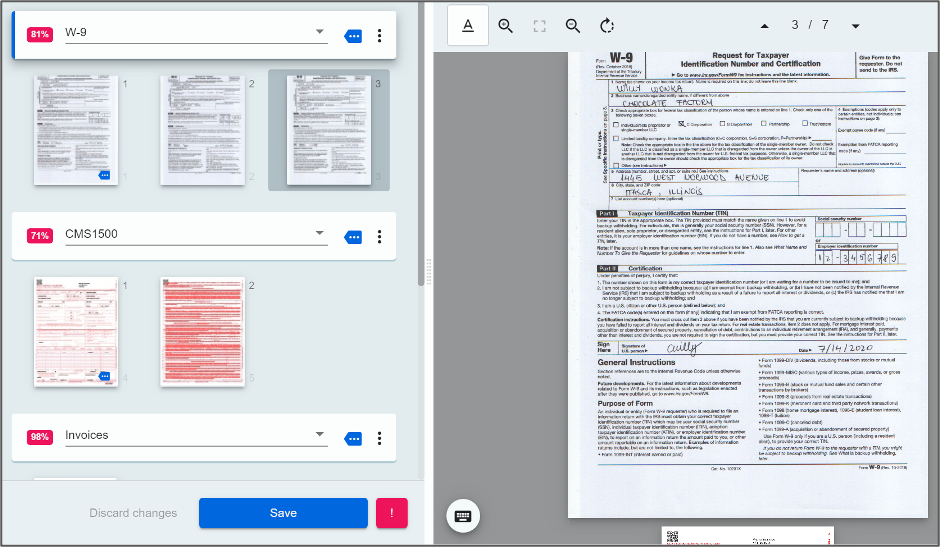
รูปภาพด้านล่างแสดงลักษณะการ classify เอกสารออกเป็นชนิดต่างๆของ UiPath Document Understanding ด้วยตัวคัดแยกหรือ classifier ที่ชื่อ Intelligence keyword Classifier ซึ่งจะให้ค่าระดับความเชื่อมั่นหรือ Confidential Level ในการ classify ชนิดหรือประเภทเอกสารมาด้วย เราสามารถใช้ค่าความเชื่อมั่นนี้มากำหนดเป็น threshold สำหรับเปิดหน้าจอValidation Station ให้ผู้ใช้งานที่เป็นมนุษย์เข้ามาแก้ไขหรือยืนยันความถูกต้องของการ classify โดยโรบอทได้ ซึ่งจากรูปภาพ ถ้าผู้ใช้งานพบว่าโรบอท classify เอกสารไหนผิด ก็สามารถทำการ drag and drop เอกสารไปอยู่ในกลุ่มที่ถูกต้องได้
ตัวคัดแยกหรือ classifier นี้มีให้เลือกใช้ได้หลายชนิดทั้งแบบที่ใช้ keyword กำหนดค่าตรงๆจากตัวอักษรบนเอกสารและแบบที่ต้องมองกลุ่มคำหรือรูปแบบข้อความในเอกสารเพื่อใช้เป็นเกณฑ์การจำแนกประเภท
การ extract ข้อมูลจากตัวของเอกสาร
โรบอทใช้ extractor ในขั้นตอนการอ่านข้อมูลจากเอกสาร จากบทความตอนที่แล้ว ข้อมูลที่ยังไม่เป็น digital เช่นเอกสารกระดาษที่ถูกสแกนเป็นไฟล์รูปภาพ จะถูกทำให้เป็น digital ด้วย OCR เพื่อให้โรบอทอ่านได้ จากนั้นจึงเป็นการ classify เอกสารให้ตรงประเภทเพื่อที่ข้อมูลจะถูก extract ด้วย extractor ตามตำแหน่งและตาม field ที่กำหนดไว้อย่างถูกต้อง
ใกล้เคียงกับการเลือก classifier เรามี extractor หลายตัวให้เลือกใช้ขึ้นอยู่กับรูปแบบเอกสารและ field ที่โรบอทต้องการอ่าน ยกตัวอย่างเช่น ถ้าเป็นฟอร์มที่มีลักษณะตายตัว มีข้อมูลที่อยู่ในตำแหน่งเดียวกันทั้งเอกสารไม่ว่าจะมีกี่แผ่นก็ตามอย่างเช่น แบบฟอร์มเคลมประกัน เราสามารถใช้ Form Extractor ได้ แต่ถ้าเรามีเอกสารที่เป็นลักษณะ semi-structured อย่างใบแจ้งหนี้ (Invoice) ที่มีทั้งส่วนที่ค่อนข้างคงที่อย่างส่วนต้นเอกสารซึ่งประกอบด้วยเลขที่ใบแจ้งหนี้ วันที่ ชื่อบริษัท และส่วนที่ไม่ค่อยคงที่อย่างส่วนตารางที่ระบุชนิดและจำนวนของผลิตภัณฑ์หรือบริการที่เราซื้อมา อีกทั้งมีความต่างกันในแต่ละเจ้าหนี้ เราสามารถใช้ ML Extractor มาช่วยวิเคราะห์รูปแบบและตำแหน่งบนเอกสาร
รูปภาพด้านล่างแสดงการกำหนด extractor ให้อ่านเอกสารแบบต่างๆที่เราต้องการข้อมูล เราสามารถใช้ extractor มากกว่าหนึ่งตัวต่อหนึ่งเอกสารได้ เช่น ใช้ Intelligence Form Extractor สำหรับอ่าน field ที่เป็นลายมือเขียนหรือช่องลายเซ็นต์ และใช้ extractor แบบอื่นเพื่ออ่านส่วนที่เหลือของเอกสาร เป็นต้น
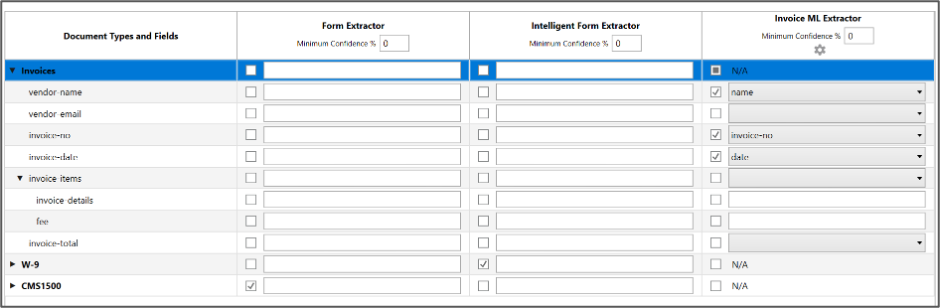
ระบบจะเลือก extractor ตามลำดับจากซ้ายไปขวาถ้าค่า confident ไม่ได้ตามที่ตั้งไว้หรือเลือกโดยค่าที่กำหนดผ่าน checkbox ตามภาพ ถ้าโรบอทอ่านข้อมูลได้เกินระดับความเชื่อมั่นหรือ threshold ที่กำหนด ข้อมูลจะถูกส่งต่อไปยังส่วนอื่นๆของกระบวนการทำงานตามที่ออกแบบไว้ แต่ถ้าค่าที่อ่านได้ต่ำกว่าค่า threshold เราสามารถออกแบบให้มีการใช้คนเข้ามา validate ข้อมูลก่อนนำไปใช้
การทำ validation ข้อมูลที่อ่านออกมาโดยผู้ใช้งาน
โรบอทจะ extract ข้อมูลจากเอกสารพร้อมกับให้ค่าระดับความเชื่อมั่นหรือ Confidential Level ว่าโรบอทมั่นใจกับค่าที่อ่านได้แค่ไหน เราสามารถกำหนดเป็น threshold ให้ระบบเปิด Validation Station ขึ้นมาให้ผู้ใช้งานที่เป็นมนุษย์เข้ามาแก้ไขหรือยืนยันการอ่านค่าของ extractor ตามรูปภาพด้านล่าง
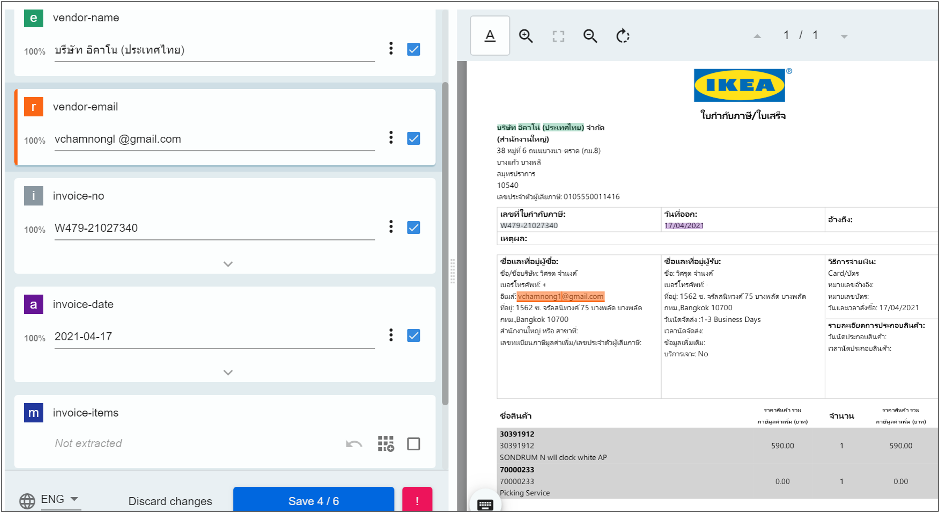
ผู้ใช้งานที่เป็นมนุษย์จะแก้ไขข้อมูลที่โรบอท extract ออกมาทางด้านซ้ายหรือยืนยันความถูกต้องผ่าน checkbox (ถ้าข้อมูลที่อ่านมาถูกต้องตามเอกสารด้านขวามือ) ในกรณีที่เลือกใช้ ML model extractor เราสามารถกำหนดให้ข้อมูลที่ได้รับการแก้ไขหรือยืนยันแล้วกลับไป train model เพิ่มเติมได้
ทั้งนี้การที่เราสามารถเลือกใช้เครื่องมือที่เหมาะสมสำหรับงาน IDP ในแต่ละขั้นตอนตั้งแต่
- การเลือก OCR Engine ที่แปลงข้อมูลรูปภาพเป็น digital ได้อย่างถูกต้องตามรูปแบบและคุณภาพเอกสาร
- การใช้ classifier ที่เหมาะสมในการจำแนกชนิดเอกสาร
- การเลือกใช้ extractor ตามชนิดเอกสารและ field ที่ต้องอ่านข้อมูล
จะทำให้คุณภาพของข้อมูลที่อ่านได้มีความถูกต้องแม่นยำขึ้น ไม่เป็นภาระให้ผู้ใช้งานต้องมา verify ความถูกต้องของข้อมูลที่โรบอทอ่านมากจนเกินไป
ผมหวังว่าบทความทั้ง 2 ตอนนี้สามารถให้ภาพแก่ท่านผู้อ่านว่าเราสามารถก้าวข้ามอุปสรรคหลายอย่างที่เกิดขึ้นอดีต ในการนำข้อมูลจากเอกสารขององค์กรมาใช้ในงาน RPA ได้หลากหลายชนิดขึ้น แม่นยำขึ้น ด้วยการใช้ AI เข้ามาเสริมการทำงานแบบ rule-based ที่ยังต้องมีอยู่
ในตอนถัดไปซึ่งจะเป็นตอนที่ 3 ของซีรี่การสอนโรบอทให้เข้าใจเอกสาร เราจะไปดูเรื่องการสอนหรือ train โรบอทจริงๆเพื่อให้ได้ ML model extractor ว่ามีขั้นตอนอย่างไรและมี model ไหนที่ได้รับการสอนหรือ pre-trained ไว้แล้ว สามารถหยิบมาใช้ได้เลยครับ
แล้วพบกันครับ
Source: UiPath Document Understanding
2 ความคิดเห็นเกี่ยวกับ “สอนโรบอทให้เข้าใจเอกสาร ตอนที่ 2 – Combining Intelligent Document Processing with RPA”
การแสดงความเห็นถูกปิด